English version available here.
Von Peter Kahlert, 28. Februar 2022
Was zeigt Dir YouTube zur Bundestagswahl 2021? Mit dieser Frage riefen wir im BMBF geförderten Forschungsprojekt DataSkop zu unserer ersten Datenspendepilotkampagne auf. Von Mitte Juli bis Ende August konnten YouTube-Nutzer*innen unsere Forschung mit einer Datenspende unterstützen.
Dazu wurde eine Datenspendeplattform eingerichtet, auf der Spendeninteressierte Informationen zu den laufenden Projekten finden können, und direkt über die Software ihre eigenen Daten einsammeln, erkunden, und schließlich — nach ausdrücklicher Zustimmung — für die Forschung spenden können. Diese Spenden ermöglichten schließlich eine Forschung mit Daten, die sich auf tatsächliche YouTube Profile beziehen und nicht auf synthetisch reproduzierte Personae. Mit den Experimenten, welche die Datenspendesoftware automatisch für die Nutzer*innen durchführt, konnten so authentische Eindrücke über die erteilten Recommendations bzw. Empfehlungen, „Autoplay“-Verläufe, YouTube‘s Newsfeed, und die Suchfunktion gewonnen werden. Das ist vor dem Hintergrund der letzten Bundestagswahl noch einmal besonders interessant und in diesem Sinne kulturell signifikant, also für die Forschung gerechtfertigt, und lädt zugleich — angesichts der Debatten um Radikalisierung und Falschinformationen — die Forschung normativ auf.
Für unser Projekt ist dies indes kein Widerspruch. „DataSkop — Was passiert mit meinen Daten?“ — so der volle Titel — ist Teil des „Digital Autonomy Hubs“, und befasst sich inhaltlich und normativ mit Selbstbestimmung in digitalen Umwelten. Mit Partnern aus Design (FH Potsdam), Medienpädagogik (Universität Paderborn & Mediale Pfade), und der NGO AlgorithmWatch, eine kritische Beobachterin von Prozessen algorithmischer Entscheidungsfindung, soll eine Datenspendeinfrastruktur entstehen, um Forschungsprojekte, wie wir sie in den Pilotprojekten durchführen, zu unterstützen. Unsere Pilotprojekte zielen auf eine kritische Forschung und aufklärende Pädagogik.
Um das ganze Projekt, seine Idee, und Konzeption besser verstehen und einordnen zu können, ist es lohnenswert, sich weitergehend mit dem Ablauf und Konzept der Datenspende selbst zu befassen. DataSkop ist nicht nur der Name des Projekts selbst, sondern auch der durch AlgorithmWatch erstellten Software, welche als Datenspendeinfrastruktur dient. Zu finden ist diese auf der wiederum gleichnamigen Website: dataskop.net. Die Anwendung kann die potentiellen Datenspender*innen zu den jeweiligen Datenspendeprojekten führen, oder in unserem Pilotfall de facto direkt zu unserem Pilotprojekt. Dafür konnte man sich innerhalb eines emulierten Webbrowsers in das eigene YouTube-Profil einloggen und so Daten über das eigene Verhalten auf YouTube verfügbar machen. Dabei wurden die Daten selbstverständlich nicht sofort gespendet, sondern erstmal zur eigenen Erkundung lokal gespeichert und von der Software verarbeitet. Erst am Ende und nach ausdrücklichem Einverständnis kommt es zu der Datenspende. Das Datenspendeprogramm läuft als Aktion en bloc ab, das heißt, wir haben kein Nutzungsverhalten in Echt-Zeit aufgezeichnet, sondern die bereits bestehende Historie, „Likes“, und Abonnements erhoben. Die übrigen Daten stammen aus automatisch durchgeführten Experimenten. Während das Programm unter dem YouTube-Profil der potentiellen Datenspender*in eine Auswahl an Seed-Videos aufruft und den je ersten Empfehlungen für sieben Wiederholungen folgt, sich den Newsfeed und zu den ersten „Schlagzeilen“ auch die Empfehlungen ansieht, und bestimmte vorgefertigte Suchanfragen stellt und die Ergebnisse mitschneidet, können Spendeninteressierte ihre Profildaten erkunden und Details zum ersten DataSkop-Pilotprojekt erfahren. Zudem gibt es einen freiwilligen Fragebogen, der demographische Details, eine Selbsteinschätzung (was wird am meisten geschaut?) und technische Angaben (z.B. ob YouTube hinter VPN genutzt wird) zur Plattformnutzung abfragt. Unterschiede konnten anhand dieser Kontrollvariablen nicht ausgemacht werden. Die Software loggt die Nutzer*innen außerdem auch automatisch aus ihren Profilen wieder aus, und führt die Beobachtungen zu Nachrichten und Suchanfragen ein zweites Mal zum Vergleich aus. Wird am Ende die Zustimmung zur Datenspende erteilt, werden die erhobenen Daten übermittelt.
Vorausgeschickt werden müssen auch ein paar Kernprobleme unserer Forschung, die zum einen von den Daten bzw. ihrer Erhebung herrühren, aber auch vom Forschungsgegenstand der Plattform selbst. Die Daten streuen nominal sehr stark, d.h. wir haben sehr viele unterschiedliche Videos erfasst. Dabei macht es keinen Unterschied, ob die nominale Häufigkeitsverteilung eher aus den Histories der Nutzer*innen oder des Empfehlungsalgorithmus selbst, z.B. den vorgeschlagenen Videos, rührt. Das macht die Daten sehr unübersichtlich, lässt aber trotzdem heuristische Schnitte zu. Es gibt ein paar wenige gut sichtbare Videos, und ein weites und unübersichtliches Feld, das sich dahinter erstreckt. Daher haben wir unsere digitalen Methoden um qualitative Taktiken erweitert und jeweils aus dokument- und mediengestützter Diskursforschung Felder, Quellen und Inhalte gesichtet, die unserer besonderen, daten-analytischen Aufmerksamkeit bedurften. Darüber hinaus haben wir die daraus gewonnenen Übersichten über Zusammensetzungen und Verteilungen für weitere, qualitative Spurensuchen genutzt. In diesem ersten thematischen Arbeitsschritt stellten wir Themen und Begriffe aus den Google-Trends sowie aus den Wahlprogrammen der parlamentarischen Parteien zusammen. Daraus bestimmten wir die unabhängigen Variablen unserer Experimente. Den massenmedialen Diskurs zur Erhebungszeit haben wir darüber hinaus beobachtet, unsere Experimente tagesaktuell angepasst und diese ‘Trends’ nach der Erhebung zur Filterung und Befragung unserer Daten genutzt.
In jedem Fall ist das Datensample, welches sich aus den Spenden ergibt, kein ausgewogenes oder repräsentatives. Allein über den Call-for-Donations, der über den Spiegel, vor allem aber effektiv über ein Video von „Ultralativ“ verbreitet wurde, ergibt sich ein entsprechender Bias in unserem Sample. Nachdem von den ursprünglich über 5000 spenden alle unvollständigen und Verfahrensfehler behafteten Datenspenden entfernt worden sind, verblieben auch nur noch knapp 2000 (exakt: 1980), von Spender*innen, die alle mutmaßlich über eine bessere Hardware und Internetverbindung verfügt haben. Die unten folgenden Ausführungen zu den Analysen beziehen sich alle auf diesen kleineren, bereinigten Datensatz (n = 1980). Ebenso lässt sich für unsere Datenspenden festhalten, dass sie vor allem von Männern um die 25, und tendenziell eher aus dem Norden Deutschlands mit leichtem Schwerpunkt auf Berlin stammen. Ihre Top-Interessen an YouTube-Inhalten sind “Gaming” (2507), “Wissenschaft & Technik” (2102), “Unterhaltung” (1541), und Bildung (1541).
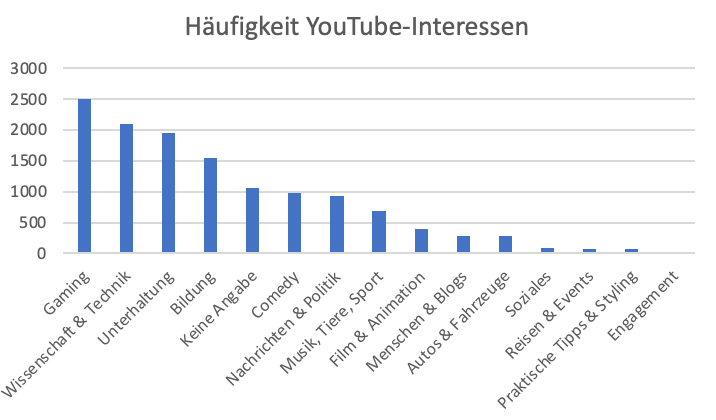

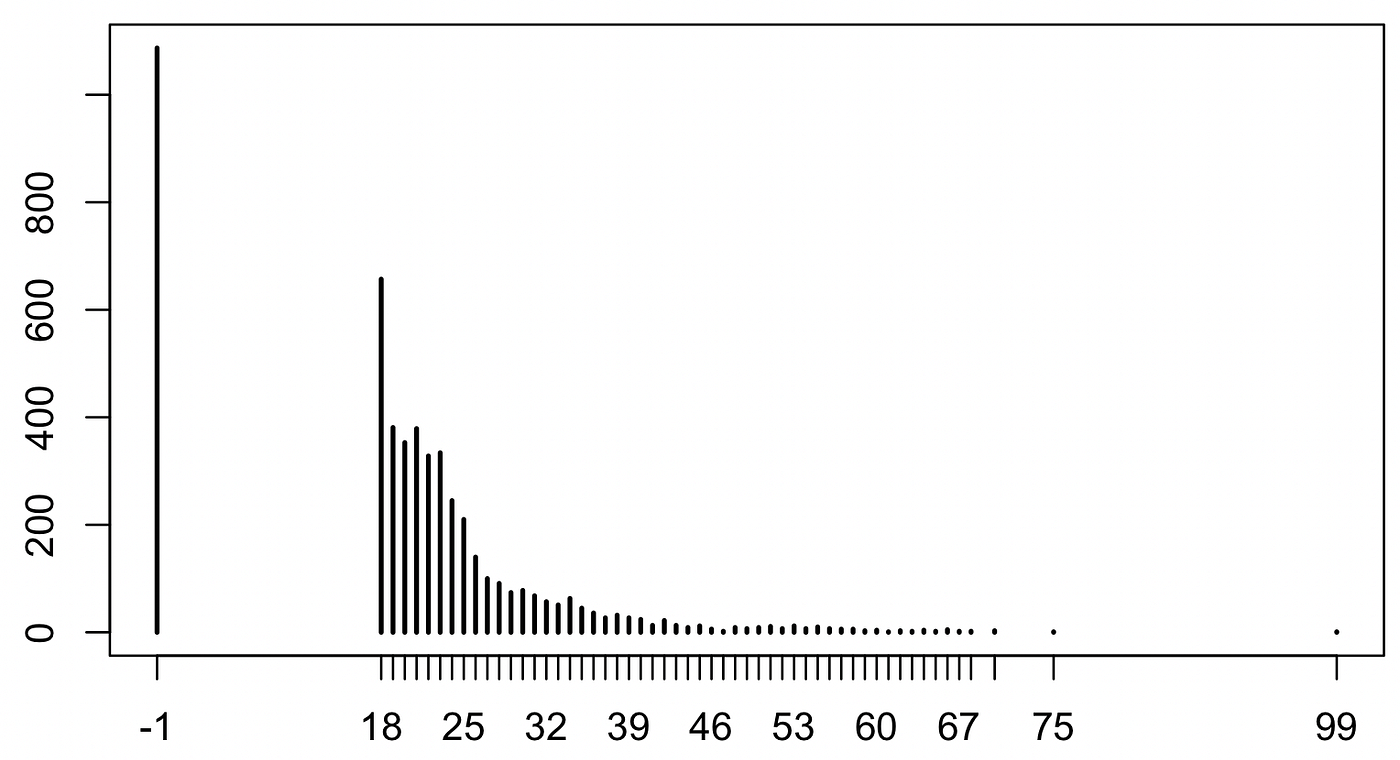
Kleinere Unterschiede sind in den Daten dennoch erkennbar, und auch ein paar wenige Schwerpunkte bzw. Videos oder Channel, die sich mehrere Spender*innen teilen, lassen sich ausmachen.

Es lässt sich etwa feststellen, dass in unserem Sample Nutzer*innen vorwiegend entweder das Video von Ultralativ zum YouTube-Algorithmus ODER das „Zerstörung der CDU“ Video von Rezo geliked haben, selten jedoch beide. Das hatte uns überrascht, reicht aber als Beobachtung bislang nicht über diesen Befund hinaus. Insgesamt streuen die Daten zu weit und zerfallen überwiegend in kleinste Einzelfälle, sodass Verbindungen ohne weitere Hilfskonstrukte nicht qualifiziert werden können. Zudem sind insbesondere die Historien teilweise überflutet mit Videos, die von den Nutzer*innen noch gar nicht angesehen wurden — mutmaßlich ein Artefakt aus automatisch abspielenden Plays auf der Plattform. Zwar lassen sich diese Videos selbstverständlich ausfiltern, machen aber in jedem Fall weitergehende Untersuchungen erforderlich und verdrängen mutmaßlich angeschaute Videos aus dem Scraping-Prozess. Ein anderes Problem an der Schnittstelle Datenspender*in/Plattform sind Inkonsistenzen die durch die Nutzung anderer nationaler YouTube-Plattformen (DE, AT, UK) und der Auswahl der Sprache entstehen. Darin unterscheiden sich nämlich, abgesehen von kleineren Problemen mit dem Parsing der Daten, mitunter die Sortierung der Kategorien — die Kohärenz steht in diesen Fällen in Frage.
Dies ist nur eines der plattformspezifischen Forschungsprobleme. AB-Tests stellen uns vor ähnliche Herausfoderungen, und ebenso problematisch ist die Veränderung der Metriken, wie die Anzahl der Likes und Dislikes, in Echt-Zeit und das gar nicht so seltene Ereignis von verschindenden Videos: so ist eines unserer Seed-Videos, nämlich das von CG Arvay zu angeblichen Langzeitfolgen der Corona-Impfung nicht mehr auf YouTube zu finden. Aber auch die öffentlich rechtlichen Rundfunkprofile, die sich in unseren Daten tummeln, stellen Inhalte wie Dokumentationen außerhalben bestimmter Veröffentlichungshorizonte auf „privat“ um.
Obschon diese Situation Forschung und Analyse zu einem schwierigen Unterfangen macht, muss jede Forschung, die sich mit solch komplexen Daten- und Modellökologien befasst, eine Sammlung von Indizien bleiben. Nicht zuletzt ist die Datenspende auch dadurch motiviert, den Nutzen synthetischer Daten zu untersuchen. Jedoch sind die Untersuchungen der Modelle selbst sowie der sozio-technischen Datenökologie, ihrer Nutzer*innen und Inhalte,zwei unabhängige Erfordernisse. Ersteres benötigt man, um sich ein modellanalytisches Urteil über die auf der Plattform implementierten Setzungen und Voraussetzungen zu bilden. Zweiteres jedoch um kritisch zu verstehen, wie es zu der schließlichen Nutzungsrealität kommt, die sich anhand der Datenanalyse nachvollziehen lässt.
So lässt sich kurz vorweg berichten: Betrachtet man rein statistisch die größten Häufungen im Datensatz findet sich kaum etwas wirklich brisantes. Die Empfehlungspfade streuen in unzählige Einzelfälle, auf der Oberfläche erscheinen wenig überraschende Massenhäufungen. Dabei macht es kaum einen Unterschied, ob die Daten organisch bzw. direkt durch Nutzung Entstehen (z.B. Watch-History) oder aus dem Recommender selbst stammen: Es gibt eine extreme Menge einzelner Items,und eine in den flachen, einstelligen Bereich auslaufenden Vereinzelung von Videos, die sich bei den meisten, manchmal auch bei allen Datenspender*innen finden lässt.

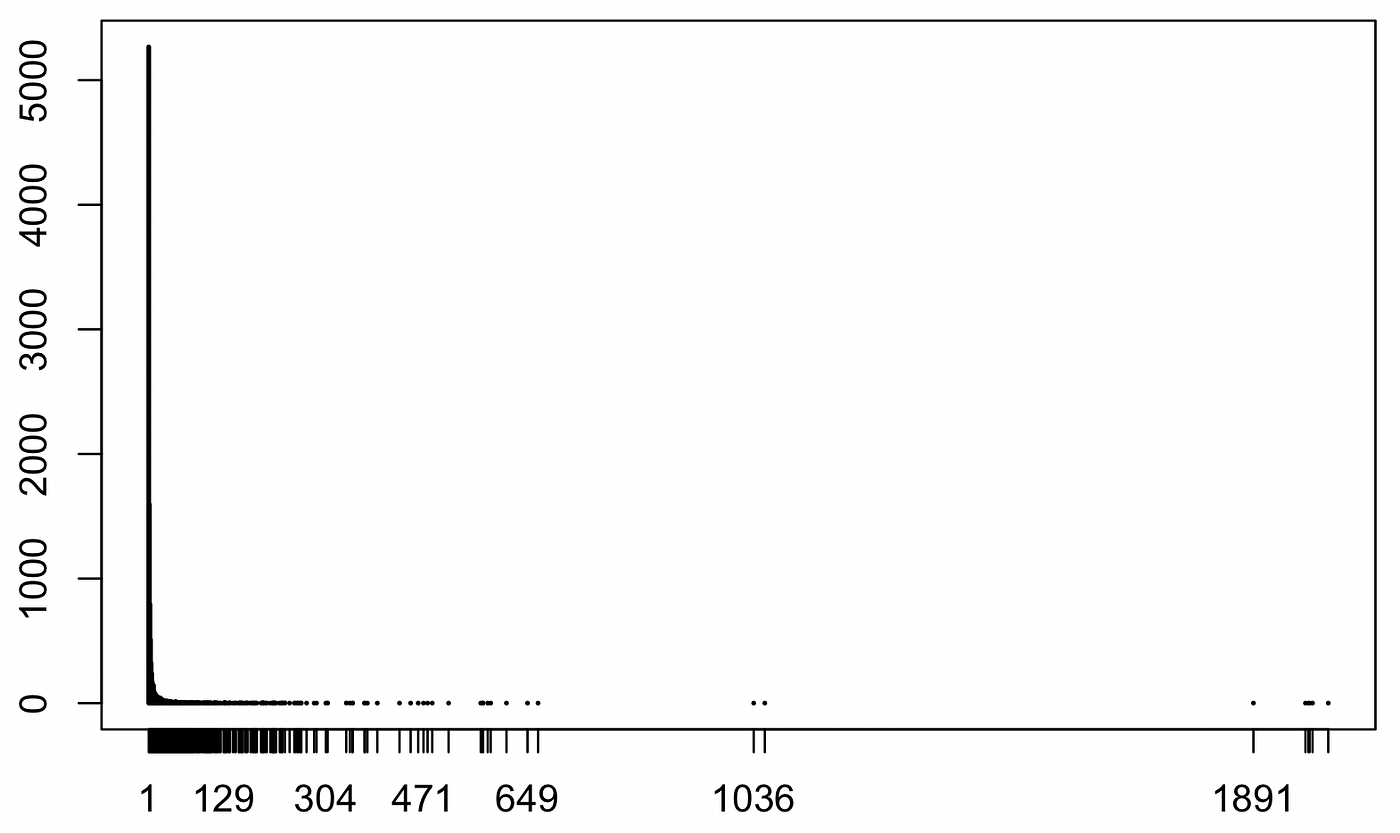
Desweitern ist der News-Feed allem Anschein nach seriös kuratiert, obschon ein Kanal den Feed in unseren Daten klar dominiert. Die Suchfunktion erscheint fast nicht personalisiert. Sieht man jedoch genauer hin, wechselt zwischen der quantitativ-analytischen und der qualitativ-deskriptiven Linse, fallen bedenkliche Grenzgänger und ganze Nischen auf. Als sozialwissenschaftlicher Partner im Projekt haben wir unsere Forschung für den ersten Projektpiloten vor allem auf reflexive Fragestellungen, Beschreibungen, und nicht zuletzt auch methodologische Experimente ausgerichtet. Ein Schwerpunkt liegt in der phänotypischen Beschreibung des Recommender-Systems, welche strukturellen und inhaltlichen Referenzen werden auf der Plattform hergestellt, und welcher Erfahrungsgehalt resultiert daraus? Dabei stellte diese Forschung ein Experimentieren mit der Methode „Datenspende“ selbst dar, ein Versuch, ihre Grenzen und Potential auszuloten, und mit synthetischen Forschungsmethoden, wie etwa der Einsatz künstlicher Personae, zu vergleichen.
Nach langer und intensiver Arbeit mit den Daten — und bevor die Mühlen des akademischen Publizierens gemahlen haben — freue ich mich hier eine kleine Auswahl an detailierten Beobachtungen und Analysen, sowie tieferere Einblicke in das dahinterliegende Forschungskonzept vorstellen zu dürfen.
Für das Suchfunktions-Experiment haben wir politische bzw. bundestagswahlbezogene Begriffe, wie Baerbock, Laschet, Scholz, ausgewählt, nach denen unsere Spender*innen YouTube haben suchen lassen, und zwar einmal mit ihrem Account eingeloggt, und einmal ohne Log-In, sozusagen ‚anonym‘ und unpersonalisiert. Dabei sollte sich jedoch herausstellen, dass die Suchergebnisse in YouTube wenig bis gar nicht personalisiert sind — zumindest für unsere Datenspender*innen und die von uns gewählten Begriffe. Wobei sich zwischen diesen ein paar, wenn auch kleinere, Unterschiede im Personalisierungsgrad beobachten lassen.
Wir haben eine Auswahl an Suchbegriffen, die vor dem Hintergrund der Bundestagswahl von uns als wahlkampfpolitisch relevant identifiziert wurden, zusammengestellt, um zu sehen, was YouTube Nutzer*innen, die in ihren Account eingeloggt waren(oder eben nicht), zeigen würde. Dazu haben wir uns mit Twittertrends, Googletrends, aktuellen Nachrichten und den Wahlprogrammen der Parteien befasst und innerhalb des Projekts diskutiert. Das Ergebnis waren sieben Begriffe für das Such-Experiment: Scholz, Baerbock, Laschet, Afghanistan, Gendern, Hochwasser, Impfpflicht, und „Bundestagswahl 2021 wen wählen“.„Hochwasser“ wurde erst kurz nach dem Start der Datenspendekampagne in die Liste aufgenommen — war doch die tragische Überschwemmung in NRW zeitgleich zum Launch unserer Plattform das dominierende Nachrichtenthema. Zuvor hatten wir uns im Konsortium auf einen anderen Wahlkampfbegriff mit Umweltbezug geeinigt: „Benzinpreis“. “Hochwasser” durch “Benzinpreis” zu ersetzten gründete auf ihrer diskursiven Verwandschaft über die Themen „Umwelt“ und „Klimawandel“. Einige der Begriffe, wie „Impfpflicht“ und „Gendern“ haben wir gewählt, weil wir uns einen polarisierden Effekt zur Untersuchung von Radikalisierungstendenzen auf YouTube erhofft haben, ohne selbst problematische Begriffe nutzen zu müssen.
Die Ergebnisse der personalisierten (eingeloggt) und anonymen (ausgeloggt)Suchanfragen unterscheiden sich kaum, wie der folgenden Tabelle entnommen werden kann.

In der Tabelle finden sich die Ähnlichkeiten für die ersten 20 Sucherergebnisse, die Reihenfolge der Videos wurde dabei nicht berücksichtigt. Auffallend sind die Suchanfragen, deren Median eine Ähnlichkeit von 100% aufweist. Dies bedeutet, dass mindestens die Hälfte der Datenspenden inhaltlich gleich ausfielen, unabhängig davon, ob ein User eingeloggt war, oder nicht. Dass dies vor allem auf wahlpolitisch relevante Begriffe zutrifft, lässt auf eine entsprechende Kuratierung und Vorsicht im Recommender-Design seitens YouTube schließen. Die Suchergebnisse basieren in unseren Daten auf keiner personalisierten Kuratierung. Zudem — so unsere These — lassen sich wenig bis kaum personalisierte Suchergebnisse besser moderieren.
Es lässt sich weiterhin mutmaßen, dass die Diskrepanz zwischen Median und arithmetischem Mittel (Ratio) auf eine Personalisierungsschwelle verweist. Das heißt, ein paar wenige Spender*innen erhalten personalisierte Suchergebnisse, während bei den meisten die Suchergebnisse kaum bis gar nicht abweichen. Eine mögliche Erklärung für dieses Phänomen wäre, dass Ergebnisse erst ab einem gewissen quantitativen Schwellenwert personalisiert werden.
Werfen wir nun einen Blick auf die Datenverteilung. So hat beispielsweise die personalisierte Suchanfrage zu „Scholz“ auf die Masse von 1980 vollständigen Datenspenden lediglich 213 verschiedene Videos in den ersten 20 Ergebnissen unseren eingeloggten Spender*innen (gegenüber 206 ohne log-in) gezeigt. Zählt man die Channel, finden wir eingeloggt nur 71 verschiedene Channel und 70 ohne Login. Es sind nur vier Channel, die abweichen, sodass sie zusammen auch nur 74 Channel zählen. Vereinigt man die einzelnen verschiedenen Video-Items, welche die personalisierte und anonyme Suche produzieren, so steigt die Anzahl der Videos nur wenig — auf insgesamt 221 (von 213 bzw. 206). Von einer Personalisierung kann also kaum gesprochen werden — dabei weist YouTube einen in den Privatsphäre-Einstellungen explizit darauf hinweist, dass ein Deaktivieren der Watch-History die Performance der Suchfunktion beeinträchtigen würde. Aus unserer Daten ist das aber nicht ersichtlich.
Vergleichen wir nun die Suchergebnisse mit dem News-Feed hinsichtlich der Personalisierung, beträgt die durchschnittliche Übereinstimmung zwischen eingeloggten und anonymen Empfehlungen zu YouTubes Schlagzeilen lediglich 15%. In diesem Fall liegt dort auch der Median und scheint damit — zumindest für unser Sample — eine Art allgemeinen Personalisierungsgrad darzustellen. Auch das Verhältnis der Thementreue zwischen Suchergebnissen und News-Feed ist auffallend. Die Suchfunktion überzeugt hier mit einer starken thematischen Übereinstimmung von Suchbegriff und -ergebnis. Die Suche nach „Impfpflicht“-Videos lieferte nur 116 nicht-themenverwandte Treffer, welche wir mithilfe unseres selbst definierten Begriffssets zu Corona indentifizierten. Die 116 Treffer setzten sich aus nur drei verschiedenen Videos zusammen. Das am häufigsten vorkommende ist ein WELT Nachrichtensender Video zum Thema Hochwasser in NRW. Bei den weiterführenden Empfehlungen zum Newsfeed sieht es hingegen anders aus. Obschon ohne Log-In etwas thementreuer, verweisen Nachrichten-Schlagzeilen zu Covid-19 eher selten auf weitere Videos, die sich auch auf Corona beziehen. Das heißt ausgehend von 75.000 Videos mit Coronabezug aus dem News-Feed verweisen nur noch 13.000 Empfehlungen explizit auf Covid-19.
In der Untersuching des News-Feeds und der Suchanfragen zeigt sich zudem eine starke Dominanz des WELT Channels. Unsere Projektpartner von AlgorithmWatch hatten sich bereits mit dem YouTube News-Schlagzeilen Bias des Springer-Mediums „WELT“ befasst (zu lesen hier). Auch im Suchanfragenexperiment schneidet WELT auffallend ‚gut‘ ab, obschon er nicht auf allen Häufigkeitslisten führt. So ist „Welt Nachrichtensender“ 18198 Mal in den Suchergebnissen (ohne Log-In) zur „Impfpflicht“, der zweitplatzierte Channel „tagesschau“ taucht nur noch 5467 Mal auf. Auch bei „Hochwasser“, „Benzinpreis“ und „Baerbock“ führt „WELT Nachrichtensender“ mit großem Abstand. Nur bei den Suchbegriffen „Laschet“ und „Scholz“ belegt der Channel nicht den ersten Platz.
In den Nachrichten und den Empfehlungen zu den Nachrichten können die öffentlich rechtlichen Angebote auf YouTube in Summe mit Springer und anderen privaten Medien mithalten. In den Nachrichten bzw. Schlagzeilen und den dazugehörenden Empfehlungen dominieren sie kollektiv eindeutig. YouTube-intrinsische Channel, also YouTuber*innen ohne Affiliation in bestehende Medieninstitutionen außerhalb der Plattform, spielen in dieser Art Newscontent eine untergeordnete Rolle, obwohl sie weite Teile der Empfehlungen bevölkern, und ganz klar das Bild unseres Autoplay-Experiments prägen. Allerdings ist dieses Verhältnis auch ein Artefakt der FUNK-Gruppe des öffentlich-rechtlichen Rundfunks, da eine große Zahl, nämlich stolze 55, der journalistisch aktiveren YouTube-Channel zu Funk gehört. Es macht ganz den Eindruck, dass bei YouTube, wie Sprecher*innen des Unternehmens auch behaupten, eine redaktionelle Kuratierung stattfindet, die aber wenig von institutionalisierten Vorstellungen eines medialen Mainstreams abweicht. Ob die Massen an Videos von „WELT Nachrichtensender“ nun aus deren Suchmaschinenoptimierungs-Qualität rühren, oder auch mit der Monetarisierbarkeit der Inhalte von privaten Medienhäusern zusammenhängt bleibt indes unklar. Auffallend ist durchaus, dass der Channel sehr viel Content produziert und Hashtags nutzt. Es lässt sich aber auch feststellen, dass „WELT Nachrichtensender“ Begriffe verwendet, die vom öffentlich-rechtlichen Rundfunk nicht genutzt werden. So führt der Channel Begriffslisten an: So ist „WELT Nachrichtensender“ sowohl der Channel mit den meisten Videos im Newsfeed, der den Begriff „Corona“ im Titel führt, zudem belegt er auch bei „Covid“ den ersten Platz. „Covid“ wird beispielsweise in den öffentlich-rechtlichen Titeln im Newsfeed überhaupt nicht genutzt.
Inhaltlich sind die Suchergebnisse wenig spektakulär. Es bedarf einer gründlichen Suche, um einschlägig verdächtige Inhalte aus dem rechten Spektrum zu finden. Explizit verschwörungstheoretisches haben unsere Experimente anscheinend nicht zutage fördern können. Wohl aber solche Formate, die auf die eine oder andere Art damit kokettieren: Dies sind neben entsprechend ‚kontrovers‘ diskutierten Anbietern wie „OE.24“, “TV.BERLIN”, “BILD” und auch Inhalte der AfD. Auch Businesscoaching Channel mit Verbindungen zu „libertär“ genannten neuen Rechten lassen sich finden aber auch solche mit unverfänglichen Inhalten, die sich an einem deutlich rechten Jargon und Framing für Titel, etc. bedienen. Dort findet man beispielsweise skurrile Formationen von YouTubern, die Videos mit „CANCEL CULTURE“ bewerben, vermeindlich politische Korrektheit zur Debatte stellen, aber selbst in ihren Video- und Channeltexten eine gendersensible Sprache nutzen. Auch bedienen sich manche dieser Channel anti-etatistischen Jargon, während sie inhaltlich gemäßigt bis konservativ auftreten. Besucht man die Kommentare zu solchen Videos, scheinen sich viele an der bloßen Oberflächlichkeit solcher Stilmittel nicht zu stören, so wie die Channelbetreiber sich offenbar an den offen staatsskeptischen, rechts-driftenden Kommentaren nicht stören. Allerdings finden diese sich in den äußeren Ausläufern, den besagten unzähligen Einzelempfehlungen. So finden sich nach den Nachrichten der Tagesschau ohne Log-In immerhin 18 Empfehlungen zum Channel „RT Deutsch“, die bis auf zwei Ausnahmen alle offen Corona-Verschwörungen befeuern. Mit Log-In finden sich immer noch zwei Videos, beide sogenannte „Corona-skeptische“ Inhalte und darin auch ein AfD-nahes. Erklärende Auffälligkeiten in der Historie ließen sich bei den betroffenen Spendeprofilen nicht finden.
YouTubes “Antwort” auf die Frage, wen man denn nun zur Bundestagswahl wählen sollte, besteht vor allem aus parteipolitischen Überblicksvideos und Bildungsmaterial zum politischen System der BRD oder zur Wahlforschung. Zu den Items, die fast allen Datenspender*innen gezeigt wurden (über 1950 von 1980) gehören etwa Titel wie „WAS SOLL ICH WÄHLEN? — REALTALK über Politik & Parteien!“, „Bundestagswahl 2021: aktueller Bundestrend (Linke | SPD | Grüne | FDP | CDU/CSU | AfD)“, oder „Einfach erklärt: Wie funktioniert die Bundestagswahl?“. Erst weiter unten in den Ergebnissen finden sich drolligere Überraschungen, wie der „große Cannabis-Check der Parteien“.
Für das Autoplayexperiment haben wir ebenfalls Startvideos (Seeds) ausgewählt, die einen politischen Bezug aufweisen und vielversprechend hinsichtlich weiterer Verzweigungen erschienen. Die folgenden Analysen betrachten die Videos über alle Empfehlungspfade hinweg. Zum einen ist der Pfadursprung selbst forschungsrelevant. Zum anderen gehört es zur Strategie des Experiments, zumindest mit einer gewissen Wahrscheinlichkeit, kleinere „Seed“-Experimente zu erhalten, also Videohäufungen über Seed-Videos und Spender*innen hinweg, die damit analytisch instruktiv sind. Unser Forschungsinteresse hatte dabei zwei Schwerpunkte: Einmal welche Konsumerfahrungen — im Sinne einer semantischen Reihenfolge — sich qualitativ erkennen und quantitativ beurteilen lassen? Und welche Formen an Empfehlungspfaden lassen sich finden, gibt es Kreisverkehre, Autobahnen, o.ä.?
Die erste Frage bezieht sich auf die Narrative und Zusammengehörigkeiten, die der Recommender abbildet aber auch selbst reproduziert. Die zweite Frage nach den Pfaden der Empfehlungen befragt die Daten konzeptionell weniger inhaltlich sondern nach ihrer Form. Hier geht es um die Phänotypen des Ökosystems YouTube. Wir wollen uns zunächst einmal die Pfade der Empfehlungen anschauen, bevor wir auch inhaltliche Dimension der Empfehlungen diskutieren.
Zeigt das Empfehlungssystem von YouTube uns in den Autoplaypfaden viele verschiedene Videos, oder wiederholen sich — auch in einem einzigen Pfad — Videos, vielleicht sogar das Seedvideo? Tatsächlich war dies öfter der Fall, als dass alle Videos eines Pfades verschieden waren. Möglicherweise ein Effekt unserer Methode — Videos lediglich aufzurufen, und nicht ganz abzuspielen — , allerdings war die Aufzeichnung der Nutzungs-Historie während des Versuchs war deaktiviert. Es ist jedoch anzumerken, dass 90% bis vollständig angsehende vollständig Videos am seltensten in den Empfehlungen auftauchen. In der Regel zeigt der Empfehlungsalgorithmus in unseren Daten noch nicht betrachtete Inhalte. Im Mittelfeld findet man eine typische U-Verteilung, offenbar hält YouTube halbgesehenes für besonders uninteressant.
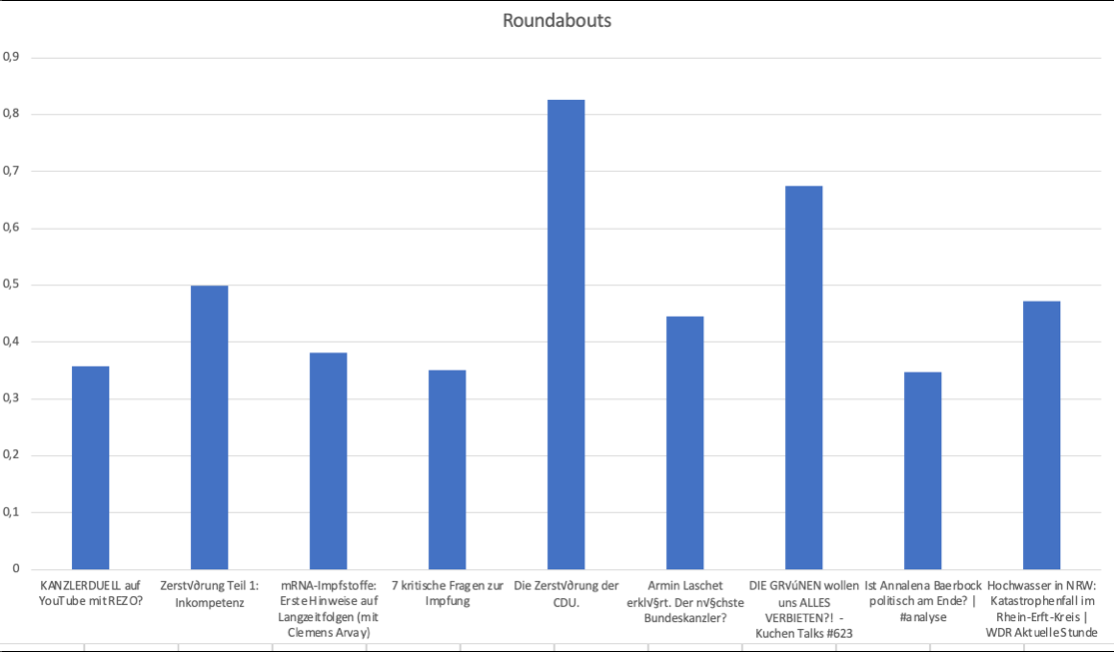
Die meisten Kreisverkehre folgten auf das „Die Zerstörung der CDU“ Videos von YouTuber Rezo. Dieses enthält nicht nur die meiste Redundanz, sondern auch die extremsten Fälle, wie vollständige Schleifen oder bis zu vier Wiederholungen. Das war einigermaßen überraschend, könnte aber am Alter des Videos liegen — zumindest wäre dies gegenüber den anderen Seeds ein klares Alleinstellungsmerkmal.
Wir sind davon ausgegangen, dass ein Video mit solcher Massenaufmerksamkeit in der Vergangenheit und über längere Zeit hinweg in der Item-Matrix im Plattform-Backend hoch aufgelöst wäre und viele feine Unterschiede zeigen würde. Tatsächlich zeigt sich aber ein anderes Bild. Die Streuung der Videos, also das Verhältnis der Zahl verschiedener Folgevideos gegenüber größtmöglichen Variation, fiel für das Rezo Video gegenüber einem aktuellen und weniger geklickten Seed-Video von Rezos Zweitchannel „Renzo“ deutlich geringer aus.
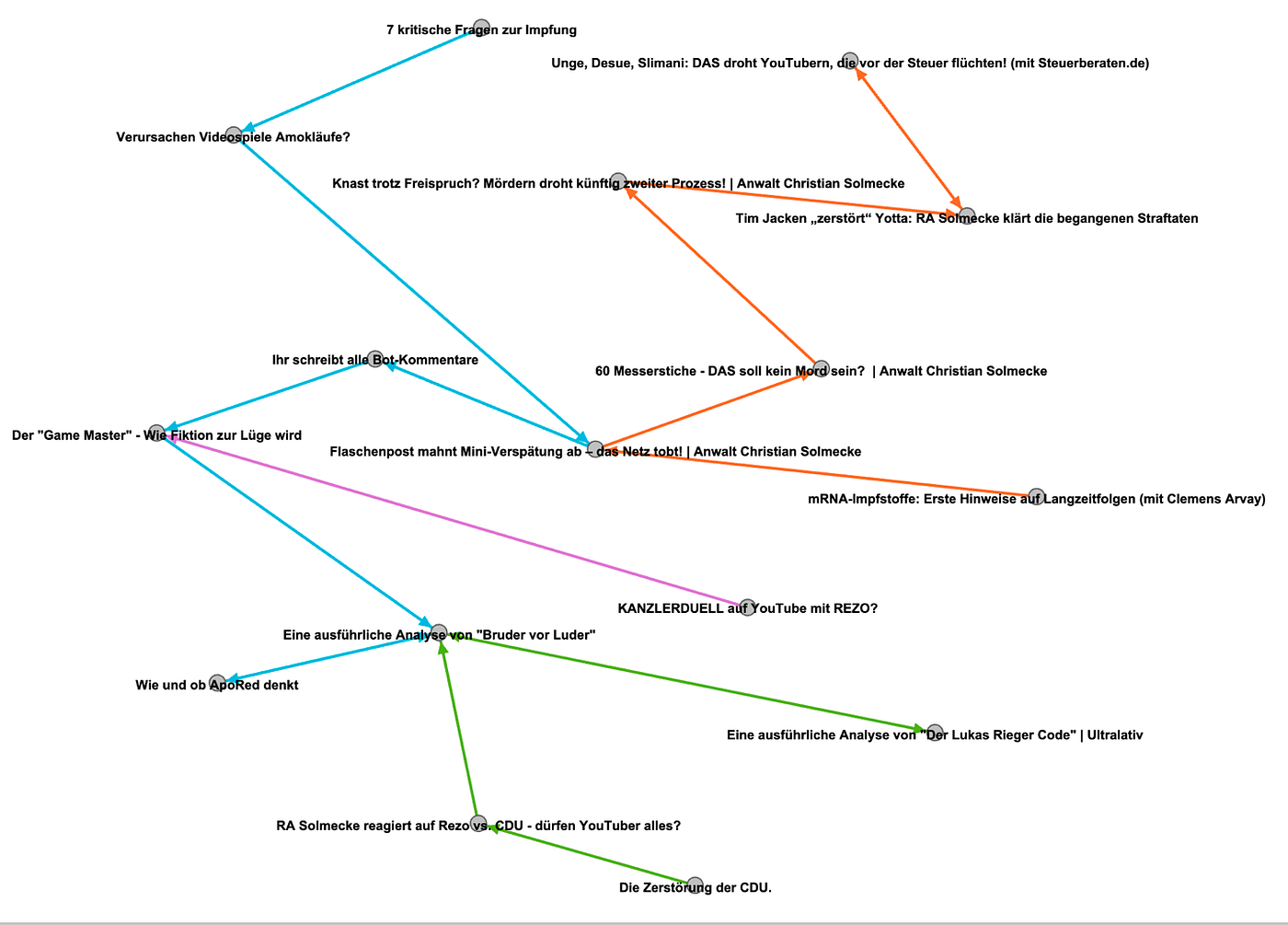
Wir haben in den Daten auch eine Art Autobahnauffahrt finden können. Oder, weniger bildhaft, ein paar Trichter.

Das heißt also, dass im Autoplaypfad einem Video zwar viele Videos vorausgehen (i.e. Eingangsgrad), aber nur wenig Videos folgen (i.e. Ausgangsgrad). Solche Trichter scheinen vor allem und bisweilen extrem (z.B. mit einem Eingangsgrad von 38 gegenüber einem Ausgangsgrad von 1) aufzutreten, wenn Formate zusammengehören. Es handelt sich also beispielsweise um mehrteilige Dokumentationen, Podcast Reihen, oder andere aufeinanderfolgende Videos. Diese rollen sich dann vorwiegend über ihre einzelnen Teile ab und laufen dann mitunter wieder in nicht trichterförmige Formate zurück. In fast allen Fällen besteht eine hohe Channel-Treue. Das heißt, der Channel eines Videos ist oft auch der Channel der Empfehlung.
Zudem lassen sich auch Weggabelungen finden. So zum Beispiel ein Renzo-Video, das einen Eingangsgrad von 8 und einen Ausgangsgrad von 56 besitzt. Mit einer Häufigkeit von 345 im Gesamtexperiment kommt es sehr oft vor, wird aber nur über acht vorherige Quellen aufgerufen. Dieses Phänomen tritt vor allem mit Channeln auf, die eine Art Cluster um unsere Seed-Videos bilden. Dieser Cluster besteht aus den Seed-Channeln selbst, direkt assoziierten Channeln, und anderen — je nach Perspektive — durchaus auch zusammenhängenden Kanälen wie „Kanzlei WBS“, öffentlich-rechtliche Sender-Kanäle, SpaceFrogs und Ultralativ (wie auch bei unserem Stichproben-Bias zu erwarten war). Besonders auffällig — und Teil des Seeds — sind die Channel von MrWissen2go. Neben den Pseudo-Gabelungen unserer Seedvideos, die in ihrer absoluten Häufigkeit die Tabelle anführen und entsprechend hohe Ausgangsgrade aufweisen, finden sich nicht nur unzählige weitere MrWissen2go Videos in unseren Daten, sondern auch eines (nämlich „Das schmutzige Geschäft mit Ghostwriting“), dessen Ausgangsgrad (neben hohem Eingangsgrad) sich durchaus mit den Seed-Videos messen kann. Zudem ist das Video von über der Hälfte der Seeds aus erreichbar. Dieses Video fungiert als eine Art Autobahn in unserem Sample. Der Kanal von Ultralativ ist ebenso auffällig. Dieser Channel stellt eine Reihe von Auffahrten dar — Nutzer*innen werden von verschiedenen Quellen (aber auch einschließlich sich selbst) hin zu weniger Referenzen (und wieder vor allem eigenen Content) geführt.
Es lohnt sich aber auch auf rare Ereignisse und Auffälligkeiten zu achten. So dreht sich der Empfehlungsalgorithmus manchmal im Kreis, oder sogar zwischen zwei Videos hin und her. Diese Kriesverkkehre oder Einbahnstraßen kommen aber seltener vor. Es gibt auffallend vielen Berührungspunkte zwischen den Empfehlungspfaden von maiLabs „7 kritische Fragen zur Impfung“ und dem Video von CGArvay (zur Person) zu Langzeitfolgen der Impfung (das Video ist wie erwähnt nicht mehr verfügbar). Über beide findet man mitunter auch zu esoterischen und anderen verschwörungsmythisch orientierten Inhalten. Es kommt selten vor und erscheint darin thematisch vermittelt — und kontrafaktisch über die Opposition verbunden: Denn einige solcher Pfade beginnen beim CGArvays Seed und finden über Inhalte des RKI zurück zu Videos deren Inhalte sich nicht auf institutionalisiertes Wissen stützen. Dabei begegnet einem auch die Figur CGArvay wieder. Der Kanal von CGArvay taucht im Datensatz — außer eben im Seed — nicht mehr auf. Dies ist ein auffallendes Alleinstellungsmerkmal dieses Seedvideos. Insgesamt entsteht der Eindruck, dass das jeweilige Ausgangsvideo gegenüber der Historie der verschiedenen Nutzer*innen die Überhand hat.
Dies kann aber ein Effekt unserer stark selbstselektiven Stichprobe sein. Deshalb arbeiten wir weiterhin an der Ergänzung der Metadaten, um die Analysemöglichkeiten zu erweitern, und die organischen Daten auch im Vergleich zu den synthetischen Daten aus der vorkonzeptionellen Phase und den Pretests zu betrachten.
Damit endet der Ausflug durch unsere Analyse. Unterm Strich verbleibt bei allen Beobachtungen und Interpretationen vor allem der Eindruck: diese Art der Plattformforschung bietet viel zu beobachten und zu beschreiben, und doch bleibt die Analyse, nicht nur in unserem Fall, ein Indizienprozess. Es gibt natürlich Spuren, denen man folgen kann, feinere, komplexere Verfahren und Nacherhebungen. Letzten Endes bleiben die Erklärungen aber selbst oft unverändert spekulativ. Sind die inhaltlichen Gratwanderungen zwischen Koketterie, Jargon, Verunsicherung, und Störung Ergebnis von direkter Interaktionen zwischen Nutzer*in und Item, oder gehören dazu auch abstraktere Content- und Semantik-Modelle? Nach welchen Kriterien findet die Kuratierung statt? Schließlich ist YouTube eine gewerblich betriebene Plattform, muss aber angesichts der infrastrukturellen Schlüsselstellung, die ihr zukommt, die Interessen von Nutzer*innen gegenüber den eigenen abwägen und auch gesellschaftliche Verantwortung nicht nur für Inhalte, sondern auch die Verbreitung und Verbindung von Inhalten übernehmen. Eine Forschung wie unsere erinnert auch an die Schwierigkeit einer solchen Aufgabe, auch für den Plattformbetreiber selbst. Ohne zu sehr mit der Komplexität der Gesellschaft zu winken: Gewiss bedarf es keiner Steuerungfantasien. Und wie das Ultralativ-Video, dessen Featuring wir einen Großteil unserer Datenspenden verdanken, ganz richtig bemerkt: Unbedingte Transparenz ist (in diesem Falle) auch keine Lösung. Wohl aber könnte Transparenz gegenüber unabhängigen Beobachtungsinstanzen helfen, so weitläufige, volatile und sich aktiv wie unwillkürlich im Wandel befindliche Plattformen inklusiv und fair zu gestalten. Aber nicht zuletzt: Trotz dieser Blickrichtung und der mannigfaltigen Limitationen und Probleme, die datenspendebasierte Forschung mit sich bringen kann, braucht es gewiss nicht weniger, sondern mehr Datenspenden: Für mehr Forschungsopportunitäten, für mehr unabhängige Betrachtung von den Unvorhersehbarkeiten, die auch in transparenten Modellen nicht abgebildet werden können. Nur mit der authentischen Zusammenlegung von Daten und Erfahrungen lassen sich sozio-technische Ökologien in ihrer historischen Spezifität erfassen.